An Introduction To CNNs And How I Used Them To Create A Live Object Detector
Computer vision has been a crucial advancement in machine learning technology. Cars now have the potential to become fully autonomous, diseases could be detected and cured much faster and so many of the world’s problems could be solved. I wanted to get a little taste of how these computer vision systems work, so I decided to build one myself.

Computer vision systems work through a subset of machine learning called convolutional neural networks, which downsize the number of pixels while still keeping the main shapes and color variations, allowing for very little computations while maintaining high effectiveness.
Why is this important? Well, the number of computations the network would normally have to do is equivalent to the number of pixels inside it — which would be the length of the picture times the width of the picture. Not to mention the number of color channels, which is the picture represented in a set of colors.

Today’s pictures are visualized in RGB (the primary colours) and thus have 3 colors. Now let’s say we have a 30-pixel x 30-pixel image that’s in RGB. The total number of pixels is 2700, not bad for a computer.
However, most of today's cameras can take pictures above 1080p. 1080p resolution has dimensions of 1080 x 1920 pixels and is usually in RGB. So for one photo at 1080p resolution, the number of input computations is 6.22 MILLION. Now imagine if you were trying to classify live video. Everything would be extremely computationally taxing and extremely slow.
You might be wondering “Why can’t we just downsize the pictures by reducing their quality?” Well, if an image is heavily downsized, it will end up losing a lot of important data such as outlines and different shapes.
So now that we know the problem, how do Convolutional Neural Networks (CNNs) downsample the picture while keeping the main parts? They do this through two methods — convolutions and pooling.

Convolutions apply a kernel over a certain field of the image and perform matrix multiplication to get the main features of the image. The kernels essentially “slide” across the picture in order to create a downsampled image. Now here is where the important terminology comes in. A kernel is applied to each channel and then combined together to create a “filter”. It is important to note that each of the kernels has different weights. For example, the red channel kernel might have a larger weight than the blue channel and therefore the red channel’s features are responded to more heavily.

After this, the kernels are combined to create a “filter” and then have a bias added on to it.
That’s it! For further convolution layers in the network, the exact same process occurs, where there are kernels for each channel and they are weighted and given biases.
The pooling layer, on the other hand, is a bit more different from the convolution layer. The concept of pooling is to extract a certain value from a set of pixels. There are two types of pooling: Max pooling and average pooling. Max pooling is where the largest value is extracted from the location, and average pooling is where the average of all the location values are extracted.
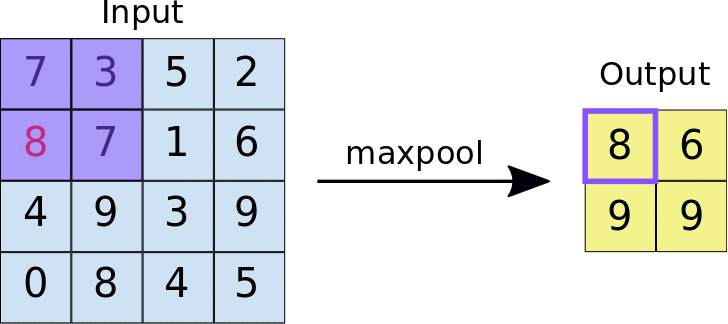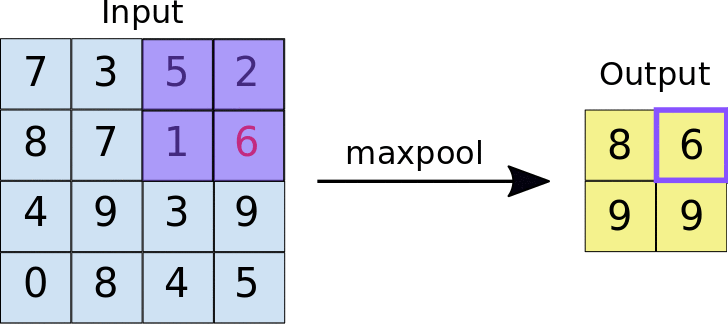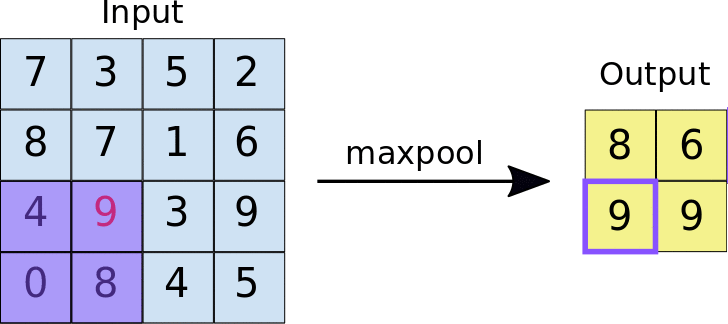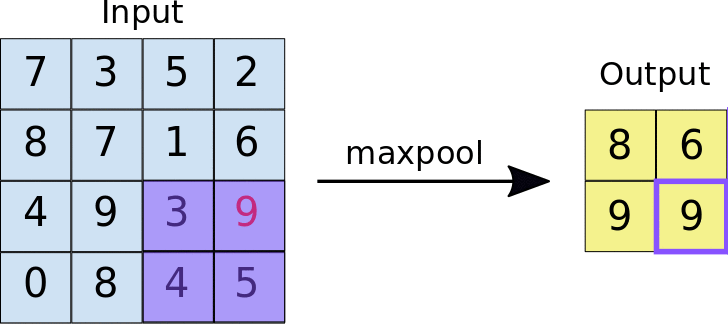
Although both methods seem relatively simple, a very good combination allows for extremely efficient object detection models that are blazing fast and still extremely efficient. A combination of these layers is called a neural network architecture, and they have been heavily optimized for efficiency. Some of them include LeNet-5, AlexNet, VGG-16 (which is the one that I used), ResNet and so many more. The model I used, called Single Shot Detector (or SSD) is based on the VGG-16, and it is one of many pre-trained models. The good thing about SSDs is that they give good accuracy while also maintaining relatively high speed, compared to You Only Look Once (YOLO) models, which are blazing fast but less accurate.

Single Shot Detector networks function by predicting bounding boxes around certain objects after several convolutional layers because more features are extracted.
The good thing about these models is that they come pre-trained to predict certain objects, such as humans, planes, couches, sofas, and many more!
Because I wanted to have the model predict on live video, the hardest portion of the project was actually converting the video feed into predictions and then outputting that. However, I had the help of a lot of very useful libraries in order for me to do this. Here’s a video of the predictor I built!
Takeaways:
- CNN's use Convolutions and Max Pooling in order to make fast and efficient predictions
- Convolutions filter out some of the data and apply weights to different channels
- Pooling is good for extracting certain features such as lines and shapes.
- A combination of these layers is called a neural network architecture, and there are many of them
- Single Shot Detectors offer high speed and high accuracy by making classification when it has more accurate data
That’s all for now! If you want to get more details on this project, such as the code and another introductory video, check out my website below!